
Se você recebeu o aviso ‘Indexado, embora bloqueado pelo robots.txt’ no Google Search Console, você vai querer corrigi-lo o quanto antes, pois isso pode estar afetando a capacidade das suas páginas de ranquearem em qualquer lugar nas Páginas de Resultados do Mecanismo de Busca (SERPS).
Um arquivo robots.txt é um arquivo que fica dentro do diretório do seu site, que oferece algumas instruções para os Rastreadores de Mecanismos de Busca, como o bot do Google, sobre quais arquivos eles devem e não devem visualizar.
‘Indexado, embora bloqueado pelo robots.txt’ indica que o Google encontrou sua página, mas também encontrou uma instrução para ignorá-la no seu arquivo robots (o que significa que ela não aparecerá nos resultados).
Às vezes isso é intencional, ou às vezes é acidental, por uma série de razões descritas abaixo, e pode ser corrigido.
Aqui está uma captura de tela da notificação:
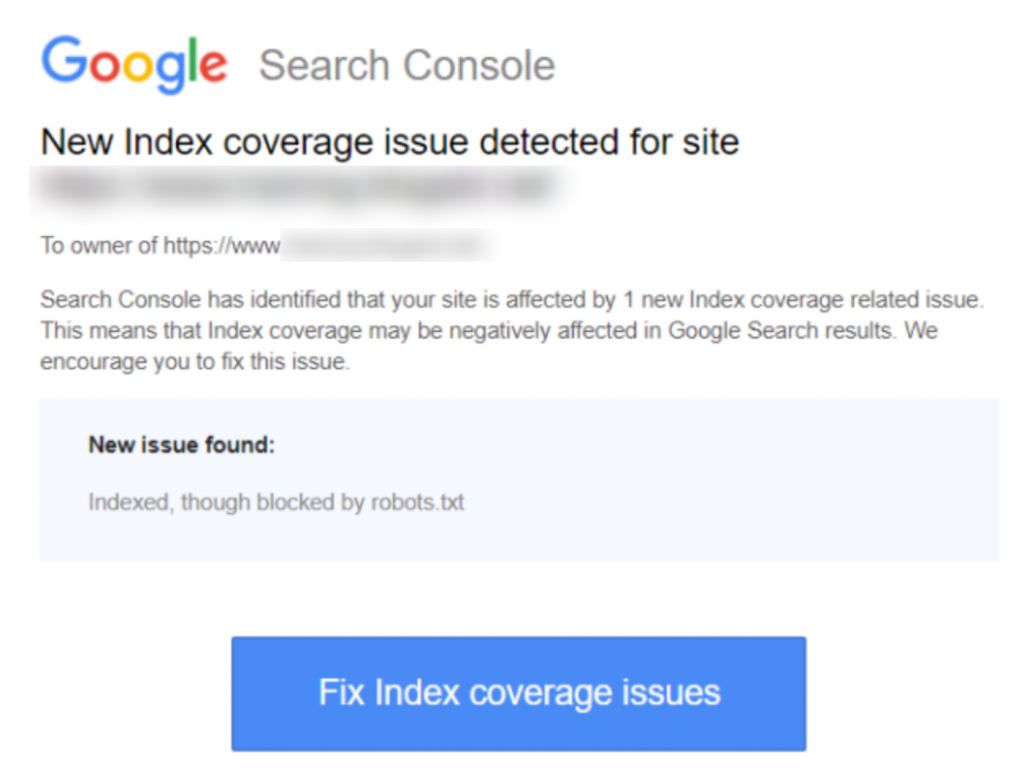
Identifique a(s) página(s) ou URL(s) afetada(s)
Se você recebeu uma notificação do Google Search Console (GSC), você precisa identificar a(s) página(s) ou URL(s) específica(s) em questão.
Você pode visualizar páginas com os problemas Indexado, embora bloqueado pelo robots.txt no Google Search Console>>Cobertura. Se você não ver o rótulo de aviso, então você está livre e sem problemas.

Uma maneira de testar o seu robots.txt é usando nosso testador de robots.txt. Você pode descobrir que está tudo bem com o que está sendo bloqueado permanecer 'bloqueado'. Portanto, você não precisa tomar nenhuma ação.
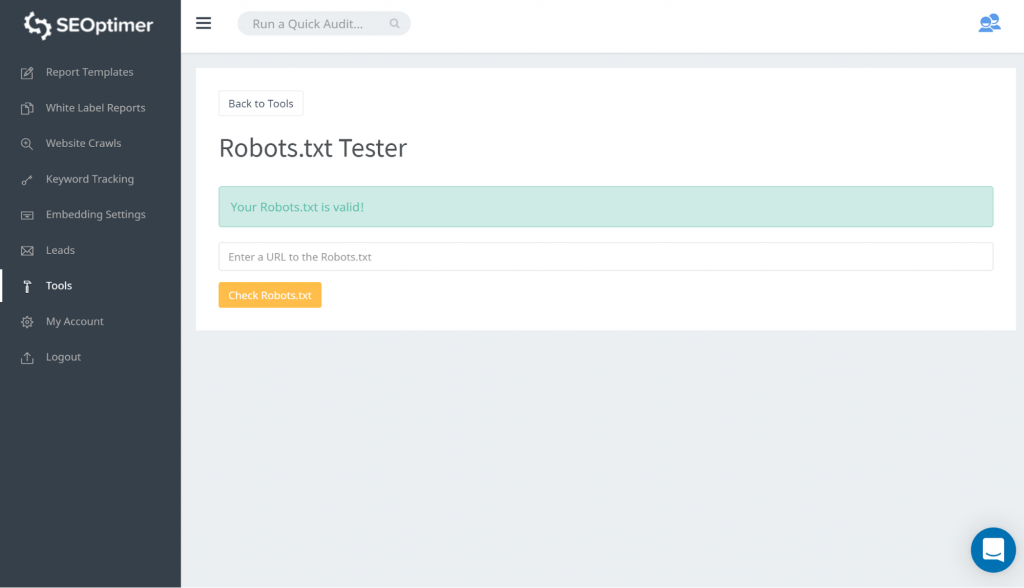
Você também pode seguir este link do GSC. Então você precisa:
- Abra a lista de recursos bloqueados e escolha o domínio.
- Clique em cada recurso. Você deverá ver este popup:
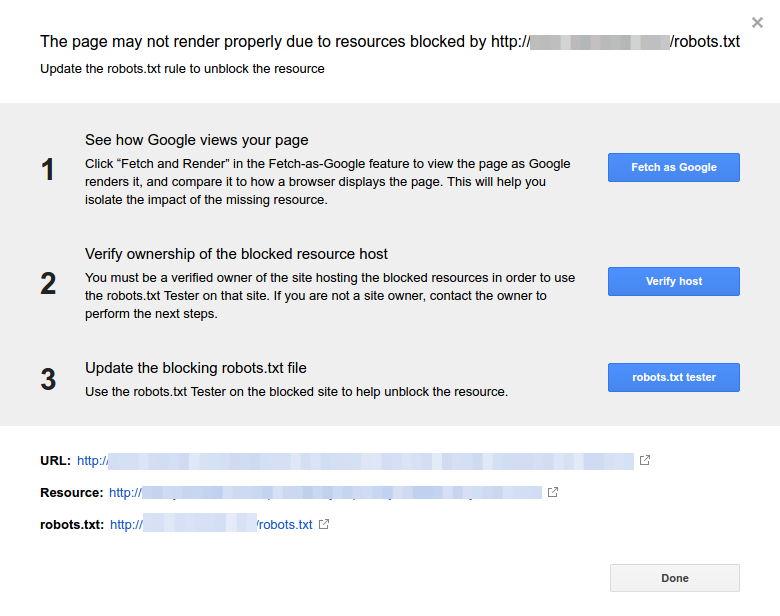
Identifique o motivo da notificação
A notificação pode resultar de várias razões. Aqui estão as mais comuns:
Mas primeiro, não é necessariamente um problema se houver páginas bloqueadas pelo robots.txt., Isso pode ter sido projetado devido a razões, como, desenvolvedor querendo bloquear páginas de /categoria desnecessárias ou duplicatas. Então, quais são as discrepâncias?
Formato de URL incorreto
Às vezes, o problema pode surgir de uma URL que não é realmente uma página. Por exemplo, se a URL for https://www.seoptimer.com/?s=digital+marketing, você precisa saber para qual página a URL é resolvida.
Se for uma página contendo conteúdo significativo que você realmente precisa que seus usuários vejam, então você precisa mudar a URL. Isso é possível em Sistemas de Gerenciamento de Conteúdo (CMS) como o Wordpress, onde você pode editar o slug de uma página.
Se a página não é importante, ou com o nosso exemplo /?s=digital+marketing, que é uma consulta de pesquisa do nosso blog, então não há necessidade de corrigir o erro do GSC.

Não faz diferença se está indexado ou não, já que nem é uma URL real, mas sim uma consulta de pesquisa. Alternativamente, você pode deletar a página.
Páginas que devem ser indexadas
Existem várias razões pelas quais páginas que deveriam ser indexadas não são indexadas. Aqui estão algumas:
- Você verificou suas diretivas de robôs? Você pode ter incluído diretivas no seu arquivo robots.txt que impedem a indexação de páginas que deveriam ser indexadas, por exemplo, tags e categorias. Tags e categorias são URLs reais no seu site.
- Você está direcionando o Googlebot para uma cadeia de redirecionamentos? O Googlebot percorre todos os links que encontra e faz o melhor para ler e indexar. No entanto, se você configurar múltiplos redirecionamentos longos e profundos, ou se a página estiver simplesmente inacessível, o Googlebot vai parar de procurar.
- Implementou o link canônico corretamente? Uma tag canônica é usada no cabeçalho HTML para informar ao Googlebot qual é a página preferida e canônica no caso de conteúdo duplicado. Toda página deve ter uma tag canônica. Por exemplo, você tem uma página que é traduzida para o espanhol. Você irá auto-canonicalizar a URL em espanhol e você iria querer canonizar a página de volta para a sua versão padrão em inglês.
Como verificar se o seu Robots.txt está correto no WordPress?
Para o WordPress, se o seu arquivo robots.txt faz parte da instalação do site, use o Plugin Yoast para editá-lo. Se o arquivo robots.txt que está causando problemas está em outro site que não é o seu, você precisa se comunicar com os proprietários do site e solicitar que eles editem o arquivo robots.txt deles.
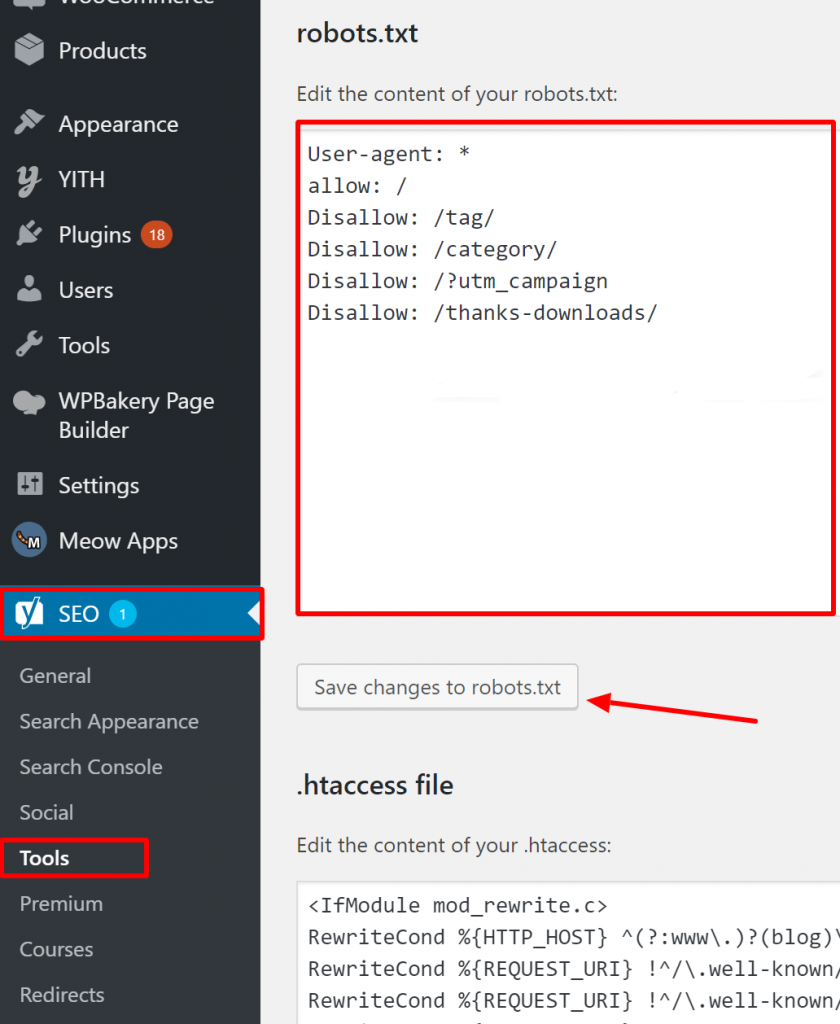
Páginas que não devem ser indexadas
Há várias razões pelas quais páginas que não deveriam ser indexadas acabam sendo indexadas. Aqui estão algumas:
Diretivas Robots.txt que "dizem" que uma página não deve ser indexada. Observe que você precisa permitir que a página com uma diretiva 'noindex' seja rastreada para que os bots dos motores de busca "saibam" que ela não deve ser indexada.
No seu arquivo robots.txt, certifique-se de que:
- A linha ‘disallow’ não segue imediatamente a linha ‘user-agent’.
- Não há mais de um bloco ‘user-agent’.
- Caracteres Unicode invisíveis - você precisa executar seu arquivo robots.txt através de um editor de texto que converterá as codificações. Isso removerá quaisquer caracteres especiais.
Páginas são vinculadas a partir de outros sites. Páginas podem ser indexadas se estiverem vinculadas a partir de outros sites, mesmo que estejam proibidas no robots.txt. Neste caso, no entanto, apenas a URL e o texto âncora aparecem nos resultados de busca. É assim que essas URLs são exibidas na página de resultados do motor de busca (SERP):
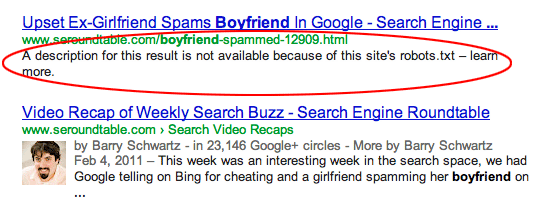 fonte da imagem Webmasters StackExchange
fonte da imagem Webmasters StackExchange
Uma maneira de resolver o problema de bloqueio do robots.txt é protegendo com senha o(s) arquivo(s) no seu servidor.
Alternativamente, exclua as páginas do robots.txt ou use a seguinte meta tag para bloquear
eles:
<meta name="robots" content="noindex">
URLs Antigas
Se você criou um novo conteúdo ou um novo site e usou uma diretiva ‘noindex’ em robots.txt para garantir que ele não seja indexado, ou se inscreveu recentemente no GSC, existem duas opções para corrigir o problema de bloqueio pelo robots.txt:
- Dê tempo ao Google para eventualmente remover as URLs antigas do seu índice
- Redirecione 301 as URLs antigas para as atuais
No primeiro caso, o Google acaba removendo URLs do seu índice se tudo o que elas fazem é retornar 404s (significando que as páginas não existem). Não é aconselhável usar plugins para redirecionar seus 404s. Os plugins podem causar problemas que podem levar ao GSC enviar a você o aviso de ‘bloqueado pelo robots.txt’.
Arquivos robots.txt virtuais
Existe a possibilidade de receber notificações mesmo que você não tenha um arquivo robots.txt. Isso ocorre porque sites baseados em CMS (Sistemas de Gerenciamento de Clientes), por exemplo, WordPress, têm arquivos robots.txt virtuais. Plug-ins também podem conter arquivos robots.txt. Estes podem ser os que estão causando problemas no seu site.
Esses arquivos robots.txt virtuais precisam ser sobrescritos pelo seu próprio arquivo robots.txt. Certifique-se de que o seu robots.txt inclua uma diretiva para permitir que todos os bots de motores de busca rastreiem o seu site. Esta é a única maneira de eles poderem identificar as URLs para indexar ou não.
Aqui está a diretiva que permite que todos os bots rastreiem seu site:
User-agent: *
Disallow: /
Isso significa ‘não proibir nada’.
Em conclusão
Nós analisamos o aviso ‘Indexed, though blocked by robots.txt’, o que significa, como identificar as páginas ou URLs afetadas, bem como a razão por trás do aviso. Também vimos como corrigi-lo. Note que o aviso não é igual a um erro no seu site. No entanto, não corrigi-lo pode resultar em suas páginas mais importantes não serem indexadas, o que não é bom para a experiência do usuário.










